Infrastructure XANADU
Architecture réseau & lab de sécurité
Résultats
- Architecture réseau complète conçue pour une entreprise de 60 utilisateurs, implémentée sur lab Proxmox
- Politique pare-feu par défaut-deny avec segmentation VLAN pour limiter la surface d'attaque
- Politique de sauvegarde 3-2-1 avec objectif RTO de 4 heures pour les services critiques
Projet académique construit autour d’une entreprise fictive, XANADU, avec 60 utilisateurs répartis sur un site principal (Atlantis) et un laboratoire distant (Springfield). L’architecture complète a été conçue sur papier, puis implémentée à échelle réduite sur un hyperviseur Proxmox : pfSense comme passerelle et pare-feu, des VMs Windows Server pour l’Active Directory et les services de fichiers, une VM Debian hébergeant la stack ERP dans Docker, et une VM Zabbix pour la supervision. L’objectif était de démontrer tous les principes fondamentaux de l’architecture cible (administration déléguée, segmentation réseau, isolation des sauvegardes, accès distant) dans un environnement de lab réellement fonctionnel.
Segmentation réseau
La question centrale : comment limiter le rayon d’impact d’une intrusion ? La réponse est une segmentation stricte par VLANs, appliquée au niveau du pare-feu.
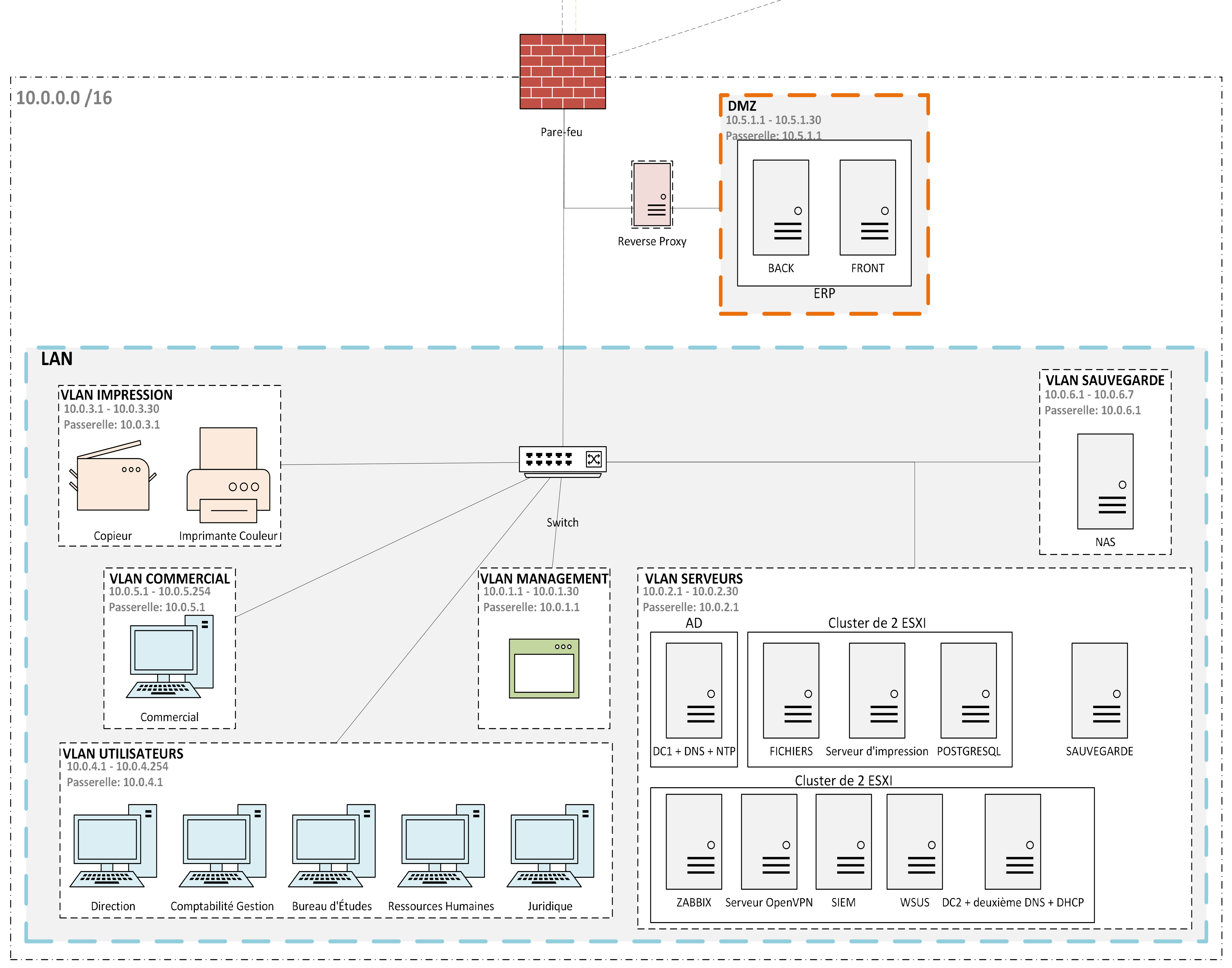
Le site d’Atlantis est découpé en six VLANs : Utilisateurs, Commerciaux, Serveurs, Management, Impression et Sauvegarde. Chaque VLAN dispose de son propre sous-réseau, et tout routage inter-VLAN passe par pfSense qui applique des règles d’autorisation explicites. Tout ce qui n’est pas explicitement permis est refusé.
Les commerciaux sont isolés car ils se connectent régulièrement à des réseaux Wi-Fi inconnus. En cas de compromission, l’attaquant reste confiné dans le VLAN Commerciaux et ne peut pas atteindre le VLAN Serveurs. Les imprimantes ont leur propre segment car elles tournent sur des firmwares non mis à jour et sans antivirus, ce sont des points de pivot classiques qui ne doivent pas avoir d’accès latéral. Le VLAN Sauvegarde est le plus restreint : seul le serveur de sauvegarde peut écrire sur le NAS, aucun poste utilisateur ne peut l’atteindre. C’est la défense principale contre les rançongiciels : la copie de sauvegarde est isolée réseau de l’environnement de production.
Une DMZ héberge les composants publics de l’ERP (frontend et backend). La base de données (PostgreSQL) reste dans le VLAN Serveurs. Le seul chemin autorisé entre la DMZ et le VLAN Serveurs est une règle de pare-feu limitée au port de la base. Une compromission complète de l’ERP laisse le tier données intact.
Liaison inter-sites et site distant
Les sites d’Atlantis et de Springfield sont reliés par un lien MPLS L3VPN. Contrairement à un VPN sur internet en best-effort, le MPLS offre une bande passante garantie et un SLA de latence contractuel (< 50 ms). Cela compte parce que les utilisateurs de Springfield accèdent à l’ERP hébergé à Atlantis via ce lien, et une latence imprévisible rendrait l’application inutilisable.
Springfield reproduit le modèle de segmentation d’Atlantis : VLANs Utilisateurs, Serveurs, Management, Impression et Sauvegarde, sur un plan d’adressage séparé (10.1.0.0/16 vs 10.0.0.0/16). Cette cohérence réduit la charge administrative et rend les règles de pare-feu prévisibles sur les deux sites.
Active Directory et tolérance aux pannes
La disponibilité de l’authentification est non négociable. Si le contrôleur de domaine tombe, personne ne peut ouvrir de session et le travail s’arrête. La réponse : deux contrôleurs de domaine à Atlantis (DC1-ATL et DC2-ATL), tous deux configurés en Catalogue Global et en réplication temps réel. Si l’un tombe, l’autre prend le relais sans intervention, aucun utilisateur n’est bloqué. Tous les rôles FSMO sont centralisés sur DC1-ATL pour simplifier l’administration.
Springfield dispose d’un contrôleur de domaine en lecture seule (RODC). Deux raisons : sécurité et disponibilité. Côté sécurité, un RODC ne stocke pas les hachages des comptes privilégiés. Même en cas de vol du serveur physique, l’attaquant ne peut pas extraire les mots de passe des administrateurs du domaine. Côté disponibilité, les utilisateurs de Springfield s’authentifient localement sans traverser le lien MPLS. Si la liaison inter-sites tombe, le laboratoire continue de fonctionner.
Administration déléguée
Plutôt que de donner des droits d’administrateur complets à chaque référent informatique de service, nous avons utilisé la délégation Active Directory pour donner à chaque référent un accès en écriture uniquement sur sa propre Unité Organisationnelle. Un référent RH peut créer et réinitialiser des comptes dans l’OU RH ; il ne peut pas toucher l’OU Serveurs, la configuration de sauvegarde, ni les données des autres services. Techniquement, cela passe par la délégation d’ACL sur chaque OU, scoped à un groupe de sécurité dédié (ex. Gestionnaires_RH).
Les GPO appliquent des bases de sécurité cohérentes sans intervention manuelle : mots de passe d’au moins 12 caractères avec rotation 90 jours, verrouillage automatique de session après 10 minutes d’inactivité, blocage des supports USB, Windows Defender configuré centralement et non désactivable par les utilisateurs, installation de logiciels restreinte aux packages signés depuis des chemins approuvés. Ces stratégies ciblent des OUs, pas la racine du domaine, ce qui permet d’appliquer des exceptions à des groupes spécifiques sans impacter l’ensemble de l’environnement.
Architecture de sauvegarde : règle 3-2-1
La crainte principale du directeur était le chiffrement de tout le SI par un rançongiciel. La défense est une architecture de sauvegarde où l’attaquant ne peut pas atteindre toutes les copies simultanément.
Nous avons appliqué la règle 3-2-1 de façon stricte :
- Copie 1 : données de production sur les serveurs
- Copie 2 : NAS local à Atlantis, isolé dans son propre VLAN, accessible uniquement par le serveur de sauvegarde
- Copie 3 : répliquée vers un NAS à Springfield via le lien MPLS (hors heures ouvrées pour respecter le budget de bande passante), et séparément vers un stockage cloud chiffré
Même si un rançongiciel compromet l’intégralité du réseau d’Atlantis, il ne peut pas chiffrer le NAS de Springfield (site physique différent, réseau différent) ni la copie cloud (airgap une fois uploadée).
Les données sont classifiées par criticité avec des objectifs RPO/RTO distincts :
| Niveau | Données | RPO | RTO |
|---|---|---|---|
| Critique | Base de données ERP (PostgreSQL) | 1 heure | 4 heures |
| Critique | Partages Direction & Juridique | 4 heures | 4 heures |
| Important | Autres partages, Office 365 | 24 heures | 24 heures |
| Standard | Dossiers personnels | 48 heures | 24–48 heures |
Pour la base ERP, des sauvegardes incrémentales horaires tournent en journée, avec une sauvegarde complète chaque nuit. Les images VM des tiers applicatif et présentation reçoivent des incrémentales quotidiennes et une complète hebdomadaire. Cela permet à Veeam Instant Recovery de remonter une VM fonctionnelle en moins d’une heure directement depuis le NAS, sans copier préalablement l’image entière.
L’Active Directory reçoit une sauvegarde complète quotidienne (état système + image VM). Restaurer un contrôleur de domaine est le chemin critique pour tout le reste, il faut donc toujours disposer d’un point de restauration récent et propre.
Les postes de travail ne sont intentionnellement pas sauvegardés individuellement. Des GPO redirigent “Mes Documents” et le Bureau vers le serveur de fichiers. Les données vivent de façon centralisée et sont couvertes par le plan de sauvegarde du serveur de fichiers. Un laptop en panne est un remplacement matériel, pas une opération de récupération de données.
Dimensionnement NAS
Volume de production : ~800 Go de partages + ~300 Go de dossiers personnels (5 Go × 60 utilisateurs) + ~20 Go ERP = ~1,1–1,5 To. Avec les incrémentales, les complètes hebdomadaires et une rétention de 90 jours, le NAS doit absorber environ 3 à 5× le volume de production. Nous avons dimensionné à ≥ 8 To en RAID 6 (double parité), qui tolère deux pannes disque simultanées sans perte de données.
Supervision et observabilité
Zabbix surveille tous les équipements en temps réel, avec alertes envoyées à l’équipe d’administration. L’intégration avec le serveur de sauvegarde fait qu’un job de sauvegarde en échec déclenche immédiatement une alerte; un échec silencieux est le pire scénario, découvert uniquement au moment où une restauration est nécessaire. Un SIEM centralise les logs de pfSense, Active Directory et des serveurs de fichiers pour la reconstruction d’incidents et les pistes d’audit.
Pourquoi ces choix
pfSense plutôt qu’une approche tout-switch managé. pfSense combine routage, pare-feu, DHCP, OpenVPN, proxy (Squid) et IDS (Suricata) dans un seul équipement open source. Pour une PME, centraliser ces services réduit la surface d’administration sans sacrifier le contrôle. Des équipements dédiés par fonction auraient été plus lourds opérationnellement et significativement plus coûteux.
RODC à Springfield, pas un DC complet. Un contrôleur de domaine inscriptible dans un site physiquement moins sécurisé est un risque : toute personne avec un accès physique et une clé USB bootable peut extraire la base Active Directory. Un RODC offre l’authentification locale et la résolution DNS sans exposer de credentials inscriptibles. Les modifications d’administration remontent toujours vers Atlantis via le lien MPLS, l’autorité reste centralisée.
VLAN Sauvegarde dédié, pas seulement des ports taguets sur le NAS. Dans beaucoup de configurations par défaut, le NAS partage l’accès réseau avec le VLAN Serveurs. Nous avons délibérément placé l’infrastructure de sauvegarde dans un VLAN séparé avec des règles de pare-feu n’autorisant que le serveur de sauvegarde à initier des connexions. Un rançongiciel qui se propage dans le VLAN Serveurs ne peut pas atteindre la destination de sauvegarde directement.
RAID 6 plutôt que RAID 5. Le RAID 5 tolère une seule panne disque. Pendant la reconstruction après une première panne, une seconde panne détruit toutes les données. Les temps de reconstruction sur des disques de grande capacité atteignent maintenant 12 à 24 heures, pendant lesquels l’array est à risque. Le RAID 6 tolère deux pannes simultanées, ce qui élimine complètement cette fenêtre de vulnérabilité.
Rotation Grand-père / Père / Fils, pas une rétention plate. Conserver chaque sauvegarde quotidienne 90 jours épuiserait rapidement la capacité. La rotation GFS conserve les sauvegardes quotidiennes 7 jours, les hebdomadaires 3 mois et les mensuelles un an. Cela offre une récupération fine à court terme (fichier supprimé hier) et une récupération grossière à long terme (conformité, obligations légales) sans croissance proportionnelle du stockage.
Politique de filtrage pare-feu
La règle de base sur chaque interface est deny-all. Chaque flux autorisé est une exception explicite avec une justification documentée. Cela force la question « ce flux a-t-il vraiment besoin d’exister ? » au moment de la conception, plutôt que d’ouvrir des règles larges en espérant que rien ne fuira.
VLAN Utilisateurs : les postes peuvent atteindre les deux serveurs DNS internes (port 53), le serveur de fichiers (SMB/445), l’interface web de l’ERP (HTTPS/443, front-end uniquement), le serveur d’impression (9100), les contrôleurs de domaine (Kerberos, LDAP, RPC, NTP, l’ensemble du jeu de ports AD), et toute IP publique hors RFC1918 pour l’accès internet. Ils ne peuvent pas initier de connexions vers le VLAN Management, le VLAN Sauvegarde, ni vers des IP de serveurs internes non listées explicitement.
Interface MPLS : le trafic de Springfield est autorisé à atteindre les contrôleurs de domaine d’Atlantis pour l’authentification, l’ERP pour le laboratoire et les bureaux distants, et le serveur de fichiers. Rien d’autre ne traverse le lien inter-sites.
Interface OpenVPN : les télétravailleurs obtiennent le même accès scopé que les utilisateurs sur site : authentification AD, ERP et serveur de fichiers. Pas d’accès plus large au VLAN Serveurs.
VLAN Serveurs : les serveurs peuvent interroger le DNS Google (8.8.8.8:53) pour la résolution externe, accéder au NTP, récupérer les mises à jour Windows et les signatures antivirus (HTTP/HTTPS vers des adresses non-RFC1918), et écrire les sauvegardes sur le NAS via SMB. Les connexions entrantes depuis les postes n’atteignent que les services ayant une règle explicite côté VLAN Utilisateurs.
VLAN Administration : la seule interface depuis laquelle les admins peuvent atteindre Zabbix (443/22), le serveur ERP (SSH/22) et l’interface de gestion pfSense (443/22). Aucun poste hors de ce VLAN ne peut initier des connexions vers des ports d’administration.
Interface WAN : une seule règle entrante : UDP/1194 pour l’établissement du tunnel OpenVPN. Tout le reste est bloqué au périmètre.
Scripts d’administration
Les opérations Active Directory manuelles sont un risque de fiabilité : une faute de frappe lors de la création d’un compte place l’utilisateur dans la mauvaise OU, ce qui signifie que les mauvaises GPO s’appliquent dès le premier jour. Nous avons automatisé les dix tâches d’administration les plus courantes avec des scripts PowerShell.
Cycle de vie des comptes. La création place automatiquement l’utilisateur dans l’OU de service correcte (OU=RH,DC=xanadu,DC=com pour les RH, etc.) afin que la stratégie de groupe s’applique immédiatement sans intervention manuelle. Un départ déclenche désactivation + déplacement vers OU=Desactive, conservant le compte pour les pistes d’audit légales sans le laisser actif. La réinitialisation de mot de passe force un changement à la prochaine connexion, de sorte que l’administrateur ne connaît jamais le mot de passe final.
Hygiène et conformité. Un rapport de comptes inactifs signale tout utilisateur ne s’étant pas authentifié depuis 45 jours, détectant les comptes de stagiaires oubliés et les absences longue durée non signalées avant qu’ils ne deviennent une surface d’attaque. Une sonde d’espace disque interroge les serveurs critiques et alerte avant la saturation (un disque plein sur le serveur de base de données ERP est un incident P1 immédiat).
Script de sauvegarde. Le script compresse les données cibles dans une archive horodatée, enregistre la taille de l’archive, et la transfère via SCP vers le dépôt distant. Il tourne dans un répertoire temporaire isolé pour éviter qu’une écriture partielle soit confondue avec une archive complète. La bande passante est limitée sur le lien MPLS pour ne pas pénaliser le trafic applicatif pendant les heures ouvrées.
Scripts de visibilité. L’inventaire des groupes exporte tous les membres d’un groupe AD cible avec leur timestamp de dernière connexion, utilisé lors des revues d’accès trimestrielles pour repérer les membres obsolètes. L’inventaire des postes résout l’état en ligne/hors ligne de chaque machine et l’utilisateur en session active, donnant au helpdesk un contexte immédiat lors du triage d’incidents. L’identification des fichiers volumineux scanne un chemin et produit une liste classée des fichiers dépassant un seuil, aidant les administrateurs à trouver les fichiers gonflant les sauvegardes (exports vidéo, snapshots VM laissés dans des partages de production).
Gestion des comptes verrouillés. Le script liste les comptes actuellement verrouillés et déverrouille un compte cible après confirmation de l’éligibilité, avec l’action enregistrée dans la piste d’audit AD. Des verrouillages répétés sur le même compte génèrent une alerte séparée, ce schéma indiquant souvent soit une attaque par credential-stuffing, soit un compte de service avec un mot de passe codé en dur obsolète.
Supervision et détection
Zabbix gère la santé de l’infrastructure (disponibilité des serveurs, état des interfaces, seuils CPU/disque/mémoire, disponibilité du lien MPLS). Wazuh agrège les logs de sécurité des DC Windows, des serveurs Linux, de pfSense et des équipements réseau, en corrélant les événements entre les sources pour faire remonter les schémas invisibles dans un seul flux de logs. Le statut des jobs de sauvegarde est intégré à Zabbix, un échec silencieux page immédiatement l’astreinte.
Dix catégories de déclencheurs sont définies, chacune avec un niveau de criticité, une source et une procédure de réponse :
| Événement | Criticité | Réponse |
|---|---|---|
| Échecs d’auth répétés sur un compte | Élevée | Alerte immédiate + surveillance du compte |
| Connexion réussie hors horaires de travail | Moyenne–Élevée | Alerte + vérification manuelle |
| Modification d’un groupe Administrateurs | Critique | Alerte immédiate + vérification de l’auteur |
| Arrêt anormal du service AD DS | Critique | Intervention d’urgence |
| Connexion entrante bloquée par le pare-feu (répétée) | Élevée | Log + escalade d’alerte |
| Échec d’un job de sauvegarde sur serveur critique | Critique | Alerte immédiate + relance manuelle |
| Espace disque sous le seuil critique | Élevée | Alerte auto + nettoyage ou extension |
| Malware détecté sur un poste | Critique | Isolation du poste + analyse complète |
| Coupure du lien VPN inter-sites | Élevée | Rétablissement d’urgence |
| Suppression massive de fichiers | Critique | Suspension du compte + restauration depuis sauvegarde |
Le déclencheur de suppression massive est le canari rançongiciel. Un ransomware chiffrant le serveur de fichiers génère un pic d’événements de modification et de suppression de fichiers que Wazuh détecte en quelques secondes, bien avant que le chiffrement soit terminé. La réponse est la suspension du compte et la restauration depuis le dernier snapshot, bornant la perte de données à l’intervalle du snapshot plutôt qu’à l’intégralité du dataset.